Where Hyperbolic Geometry Helps (and Where It Doesn’t)
A write-up of our prototype-embedding study on WikiArt. Hyperbolic geometry adds something a Euclidean prototype doesn’t, but only on one of the three things you might want it to do.
TL;DR. Hyperbolic prototype classifiers improve on a strong CLIP baseline at one specific thing: preserving the local part of a style hierarchy, meaning the structure of the nearest-neighbor graph. They lose on classification. They tie on global tree fidelity, in a way that flips sign depending on which reference tree you anchor against. Across 150 runs and three reference trees, that local advantage is the only claim that survives every robustness check. So the answer isn’t “hyperbolic wins.” It’s “hyperbolic helps locally, and only locally.”
Paper & code: github.com/pgrindehollevik-harvard/hyperbolic
Why this question
The hyperbolic-image literature (Khrulkov et al. 2020; Ganea, Bécigneul & Hofmann 2018) keeps circling the same intuition, and it’s a good one. Real-world category structure tends to look like a tree, and a tree’s leaf count grows exponentially with depth. The Euclidean ball doesn’t do that. Its volume grows polynomially in $r$. The Poincaré ball does. Its volume grows exponentially in $r$. So if you have to embed a tree, hyperbolic geometry gives you more room exactly where you need it, near the leaves.
That argument is mathematically tight, but in practice it leaves a lot of room. A lot of positive results in this area sweep one or two hyperparameters at one or two depths and report a single representative number. I wanted to see whether the advantage was load-bearing, or whether it was an artifact of which tree you happened to evaluate against. So we built a sweep that varies dimension, curvature, and a tree-aware regularizer, then re-ran the whole thing against three different reference trees.
WikiArt is a useful testbed precisely because the hierarchy is contested. Art historians actually disagree about lineage, which means there’s no canonical “right answer” to evaluate against. That makes the question sharper. Is there a geometric improvement that’s robust to which reasonable hierarchy you pick?
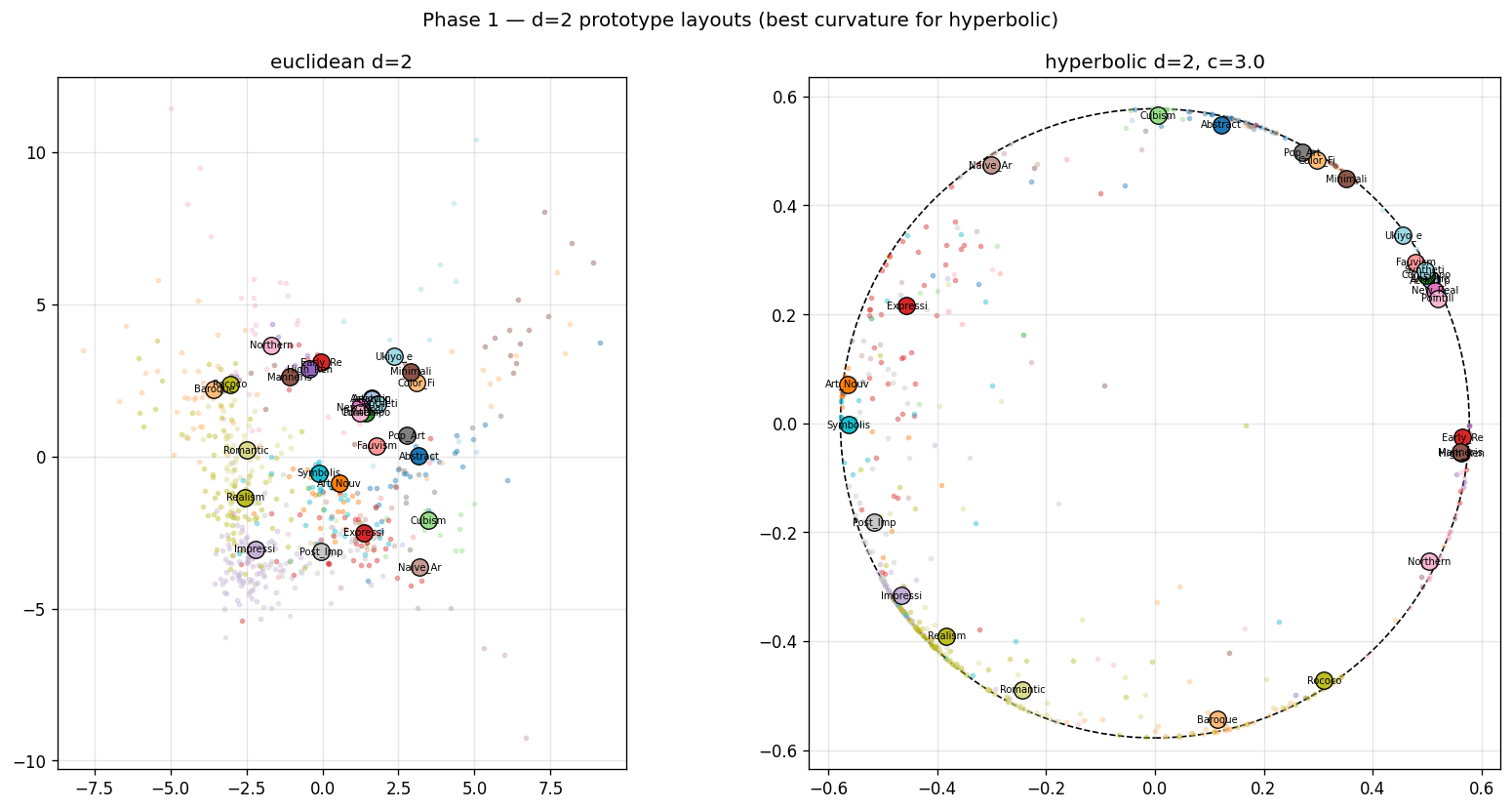
The setup
We use WikiArt Refined, around 81k paintings labeled with one of 27 styles, with a comically lopsided distribution (Impressionism has 13,060 paintings, Analytical Cubism has 77). Features come from a frozen CLIP ViT-B/16 encoder. A two-layer MLP maps those features into a $d$-dimensional embedding. A prototype classifier (one learnable point per style) turns the embedding into 27-way logits via $-d(z, p_k)$.
Switching from Euclidean to hyperbolic changes exactly two things:
- the head’s final transform: identity in the Euclidean case, the exponential map at the origin in the hyperbolic case, $\exp_0^c(u) = \tanh(\sqrt{c}\,\|u\|)\,u/(\sqrt{c}\,\|u\|)$;
- the metric used by the classifier: $\ell_2$ in the Euclidean case, the Poincaré distance in the hyperbolic case,
$$d^c(x, y) = \tfrac{1}{\sqrt{c}}\,\operatorname{arcosh}\!\Bigl(1 + \tfrac{2c\,\|x-y\|^2}{(1-c\|x\|^2)(1-c\|y\|^2)}\Bigr).$$
Everything else is shared: backbone, MLP width, dropout, batch size, optimizer, schedule. The hyperbolic prototypes live on the manifold and get optimized with Riemannian Adam via geoopt. The Euclidean prototypes use plain Adam. Caching CLIP features as fp16 tensors keeps each run under ten seconds, so the whole sweep finishes in about half an hour on a single Apple-silicon GPU. The fact that the experiment is this cheap is part of why we were willing to be patient with it.
We sweep three axes:
- Dimension: $d \in \{2, 4, 8, 16, 32, 64\}$.
- Curvature: $c \in \{0.1, 0.3, 1, 3\}$.
- Tree regularizer strength: $\lambda \in \{0, 0.1, 0.3, 1, 3\}$.
Every headline configuration is replicated across three seeds. 150 runs total.
One design choice that mattered: a hierarchy-aware loss
Cross-entropy on prototypes only asks the prototypes to be class-separable. It does not ask them to be arranged in any particular geometric pattern. That’s a real problem if you want to evaluate against a hand-built tree, because failure becomes ambiguous. Was the geometry insufficient, or did the loss never ask for the tree structure in the first place? We didn’t want to spend the paper guessing.
So we add a regularizer that pushes the prototype distance matrix toward the tree distance matrix:
The trick that mattered was the mean normalization. Tree distances are small integers. Sibling pairs are 2 apart, the deepest pairs are 13 apart on the default tree. Prototype distances, on the other hand, want to be large in whatever units classification cares about, since well-separated prototypes are easier to classify. Without normalization, the loss would force prototype distances to match tree distances in absolute units, which fights classification directly. Dividing each pair vector by its own mean before the squared difference constrains only the shape of the prototype distance matrix, not its scale. The geometry is free to pick whatever scale classification likes best. With $\lambda = 0$ we recover the standard CE-only setup. With $\lambda > 0$ we’re explicitly asking the prototypes to lay themselves out like the tree.
It runs over the $\binom{27}{2} = 351$ off-diagonal style pairs once per gradient step. The cost is essentially nothing.
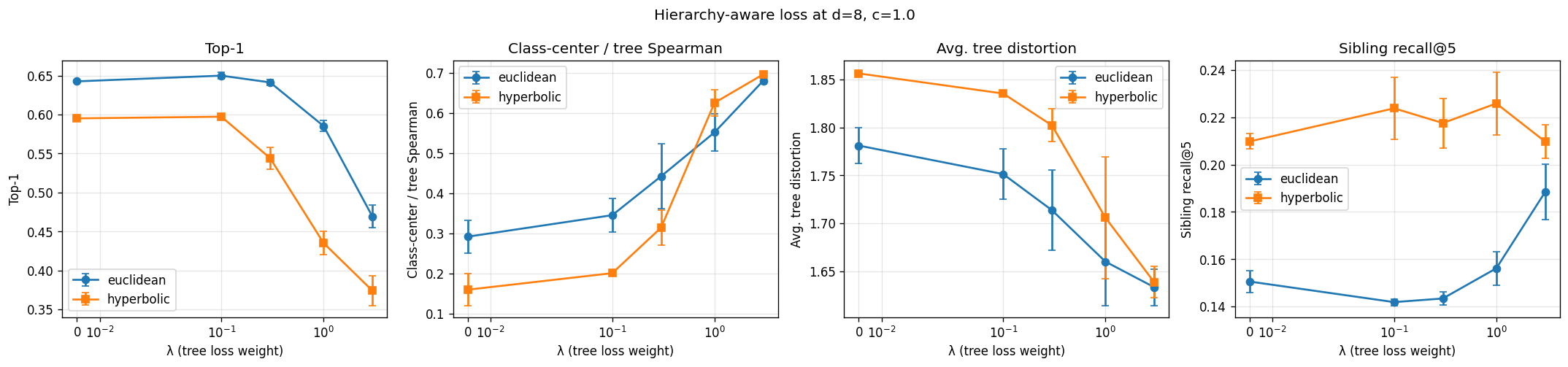
Local hierarchy preservation
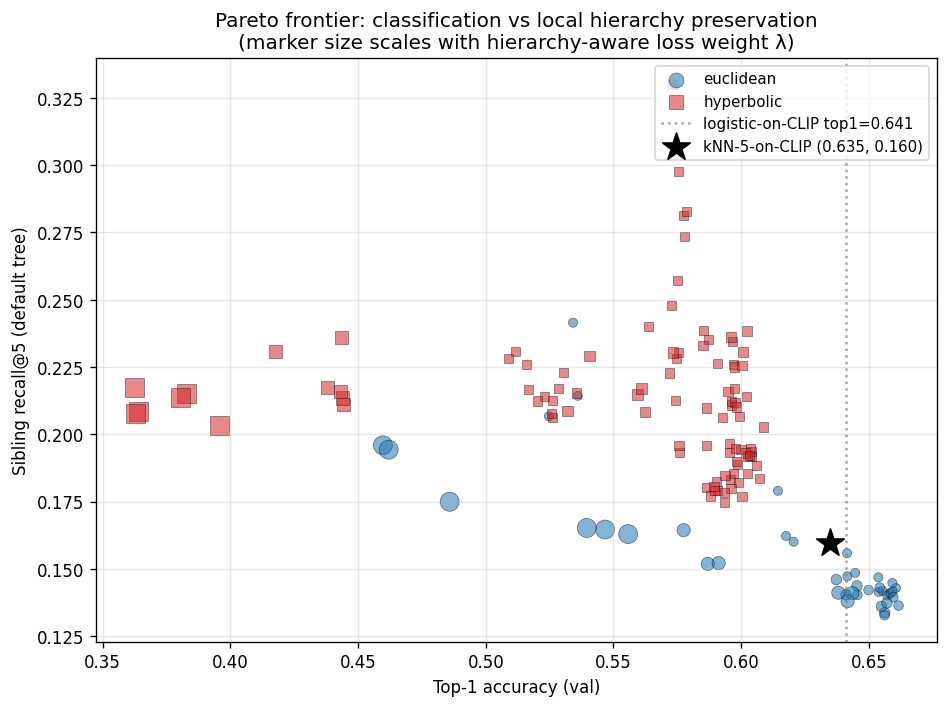
The metric that ended up mattering most was sibling recall@5: out of the five nearest neighbors of a validation embedding, how many share a parent with the query in the reference tree? It’s a local question. It doesn’t ask whether the embedding got the whole global structure right. It just asks whether the immediate neighborhood looks tree-like.
Here’s the result at $d = 8$ against the default hand-built tree:
| Model | Sibling recall@5 |
|---|---|
| $k$-NN on raw CLIP features | 0.160 |
| Euclidean prototype | 0.149 |
| Hyperbolic prototype | 0.195 |
Two things stood out. First, the Euclidean prototype is essentially tied with the encoder’s own nearest-neighbor structure. Training a Euclidean head doesn’t add local hierarchy on top of what CLIP already gave us. Second, the hyperbolic prototype beats $k$-NN-on-CLIP by 3.5 percentage points. That makes the hyperbolic prototype the only model in our whole suite that meaningfully improves on the encoder at this metric.
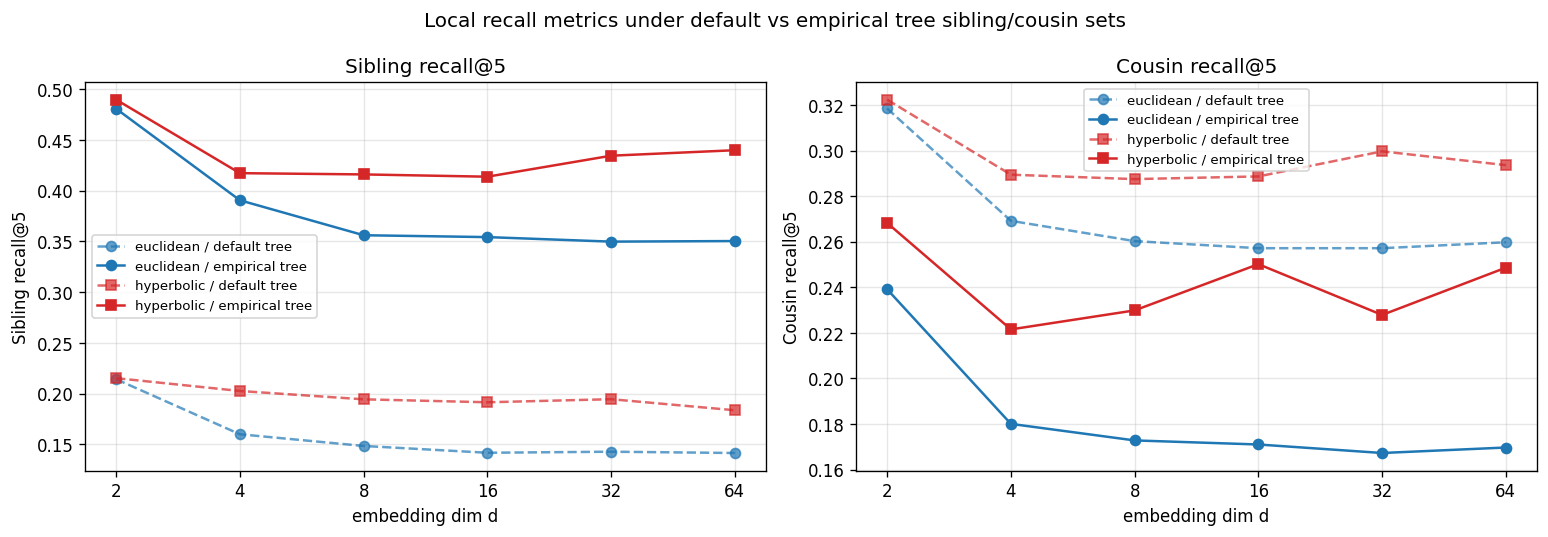
The obvious worry is that we’re measuring against our own tree, so maybe the sibling sets we chose are doing the work. To check, we rebuilt the reference from scratch in two different ways: a CLIP-derived empirical tree (UPGMA on feature centroids), and a DINOv2-derived empirical tree. The advantage held both times. Against the CLIP-empirical tree at $d{=}8$:
| Model | Sibling recall@5 (empirical) |
|---|---|
| $k$-NN on raw CLIP features | 0.366 |
| Euclidean prototype | 0.356 |
| Hyperbolic prototype | 0.416 |
Aggregated over the 18 paired (dim, seed) comparisons in the main sweep, picking curvature per pair, hyperbolic beats Euclidean by +8.7 pp on sibling recall and +15.2 pp on cousin recall (paired-$t$ $p < 10^{-4}$, sign-agreement 0.94). This is the strongest claim our experiments support, and the only one that survived every robustness check we threw at it.
Why the local advantage is real
The $d{=}2$ Poincaré-disk figure earlier in the post is the most direct evidence I have. The Euclidean prototypes sit near the origin, with no boundary to push against. The regularizer satisfies its shape constraint, but the metric never gets reshaped around the prototypes. The hyperbolic prototypes get pinned to the boundary, because that’s where the regularizer minimum lives in this geometry. The Poincaré metric then does the rest: distance compresses near the center and stretches near the edge, so the neighborhoods around boundary-pinned prototypes are exactly the kind of tight, sibling-rich sets that sibling recall@5 measures.
The Euclidean prototype with the same regularizer can satisfy the same shape constraint. It just doesn’t get the local concentration for free. The loss tells it where to put the prototypes. It doesn’t reshape the metric around them. So local recall stays at the encoder’s baseline. Hyperbolic doesn’t just place the prototypes well. The metric carries the structure outward into the neighborhood, and that’s what we were measuring.
Where it doesn’t help: classification
The classification story is real, but it doesn’t tell you much about the geometry. Top-1 accuracy:
| Model | Top-1 |
|---|---|
| Logistic regression on raw CLIP features | 64.1% |
| Euclidean prototype | 64.3% |
| Hyperbolic prototype (best curvature) | 59.8% |
The 4 to 6 pp Euclidean-vs-hyperbolic gap is robust across configurations and weighting schemes. But the Euclidean prototype isn’t doing classification work that a linear head on the same input couldn’t do. We resisted calling Euclidean the “winner” here. The right framing is that Euclidean prototype distances don’t distort classification beyond what the encoder already supports, while hyperbolic prototype distances do.
This makes sense if you think about what the geometry is for. The Poincaré metric concentrates distance near the boundary. That’s exactly what makes it good at separating fine-grained sibling structure. It’s also exactly what makes it badly suited to the kind of broad, mostly-linear separability that CLIP’s feature space already gives you.
Where the story gets unstable: global tree fidelity
If hyperbolic geometry helps locally and hurts classification, the next obvious question is whether it helps globally. Does the whole prototype layout look more tree-like? This is the section of the paper where we make the smallest claim, and not by accident.
Mean tree distortion is significantly lower for Euclidean prototypes against the default tree ($p < 10^{-4}$). The prototype-to-tree Spearman correlation, on the other hand, isn’t significantly different from zero across the full sweep ($p = 0.68$). And the small gap that does appear flips sign depending on which encoder we use to build the empirical reference tree. CLIP-empirical favors hyperbolic. DINOv2-empirical favors Euclidean. The two empirical trees correlate at 0.50 on pairwise distances, so the encoders broadly agree on similarity structure. But the global-Spearman gap between geometries doesn’t survive the encoder swap.
Global tree fidelity is a coin flip on this dataset. Local hierarchy isn’t.
The lesson I took from this was more about reference trees than about geometry. When you build the reference tree out of an encoder’s features and then evaluate an embedding trained on the same encoder’s features, you have a real circularity problem. The empirical-tree robustness check is mostly an exercise in seeing how much that circularity matters. For global metrics, the answer turned out to be “enough to flip the sign,” which is sobering.
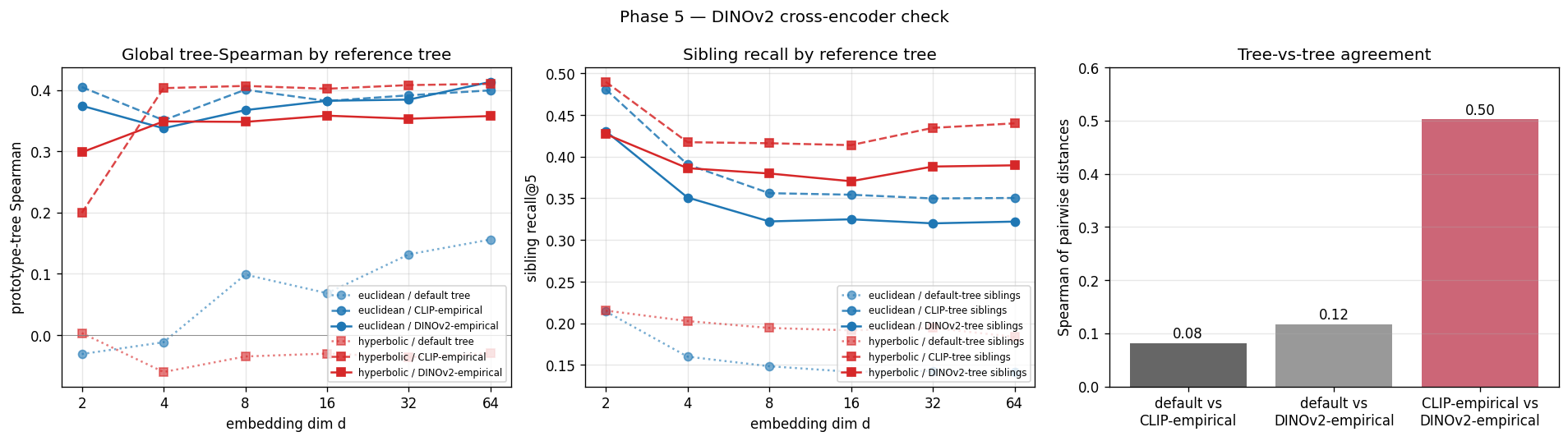
What we can’t conclude
A few honest limits, since they kept nagging me:
- The whole study lives on a 27-leaf, Western-canon-heavy taxonomy. WikiArt’s hierarchy is shallow. The literature suggests hyperbolic helps most where the hierarchy is wide, which is a regime we didn’t get to test.
- The encoder is frozen. We don’t know whether the local advantage survives fine-tuning, or whether a properly hyperbolic MLP head (Möbius layers and all) would close the classification gap.
- The empirical reference trees are themselves built in Euclidean space (UPGMA on Euclidean distances). Building one in hyperbolic space would close the remaining circularity, and we didn’t get there.
Three natural extensions, in rough order of cost-to-payoff: a fully hyperbolic head, a hyperbolic empirical-tree construction, and replication on a deeper hierarchy like iNaturalist + WordNet.
What this could amplify
Hyperbolic geometry tightens local neighborhoods. That’s the headline result, and I’m genuinely happy about it. But “tighter neighborhoods” cuts both ways when the underlying data is itself biased. WikiArt has 27 styles, and exactly one (Ukiyo-e) sits outside the European-and-American canon. East Asian ink-painting traditions that span centuries collapse into that single label. A retrieval system trained on this data will under-rank non-Western works for ambiguous queries, and a hyperbolic embedding will make those tight, confident, under-ranking neighborhoods even tighter.
That’s worth saying out loud, separate from the technical claim. The geometry is doing what it’s supposed to do. What it’s amplifying is the data.
What I took away
Before doing this project, I treated the hyperbolic-vs-Euclidean question as a yes/no question. After 150 runs, three reference trees, and a regularizer that closes the loss-ambiguity gap, I think the right framing is scale-dependent. Hyperbolic geometry doesn’t globally rearrange a representation in a way that matches a tree. It locally restructures the neighborhood of each class in a way that respects a tree. Those are different claims, and a lot of the prior empirical disagreement in this area, I now suspect, comes from conflating them.
The thirty-second version: hyperbolic prototype geometry adds local-retrieval value over a strong encoder when a Euclidean prototype doesn’t, and that local advantage is robust to which of three reasonable reference trees you evaluate against. Everything else (classification, global Spearman, mean distortion) either goes the other way or doesn’t replicate across reasonable variations of the question.
That’s a smaller claim than I went in hoping for. But it’s the one I trust.
Thanks for reading.
© Peter Flo